If you familiar with security compliance requirements such as PCI DSS or HIPAA – one of the requirements is “application whitelisting”. Application whitelisting is the solution that allows execution of pre-approved apps and scripts only and disallow rest.
Application whitelisting can be done using many tools – in this example I will discuss how to get application whitelisting done using in-build Windows tools; I will use Windows AppLocker utility to implement application whitelisting. I will discuss setting up Splunk for AppLocker, so that we get real time visibility/analytics of application whitelisting and alerting.
This HOWTO got two parts –
Part 1 – this discuss technical steps regarding how to setup application whitelisting on Windows platform and push the settings to bunch of windows computers.
Part 2 – this discuss technical steps regarding how to get visibility, analytics and alerts about the application whitelisting using Splunk (e.g. application whitelisting logs showing which apps are allowed, which are denied, who executed the app, when, from where etc).
Part 1 – Setting up the Application Whitelisting on Windows
Following are the steps for Part 1.
Step1: Start the “Application Identity” (AppIDSvc) service & set to start automatic
AppIDSvc service is a Microsoft service used by AppLocker to determine and verify the identity of an application. Without AppIDSvc AppLocker is unable to determine and verify application, scripts, installers and executables.

Step2: Setup Application Whitelisting using “Local Group Policy Editor” or “Group Policy Management Console”
AppLocker settings are available within “Computer Configuration -> Windows Settings -> Security Settings -> Application Control Policies -> AppLocker”. In an ideal environment all the AppLocker settings should combines into a single Group Policy Object (GPO) and pushed onto computers via Active Directory.
Set the policy “Enforcement rules” first
Right click on the AppLocker -> go to Properties -> Select “Enforcement rules” for both Executables and Scripts. Enforcement rule enforces “allow” and “deny” operations.
“Executable rules” are applied to application programs installed on the Windows OS.
“Scripts rules” are applied to all scripts available on the Windows OS.
“Audit only” – this setting does not prevent execution rather it generates audit logs only about what items are executed on the Windows OS and who executed it.

Set the Executable Rules
Set allow or deny action to executable application here; few options available here –
Executable Rules based on “Publisher” – allow all signed software by authorised publisher.
Executable Rules based on “Path” – allow specific file or folder. I prefer this.
Executable Rules based on “File hash” – this is for application which are not sighed.
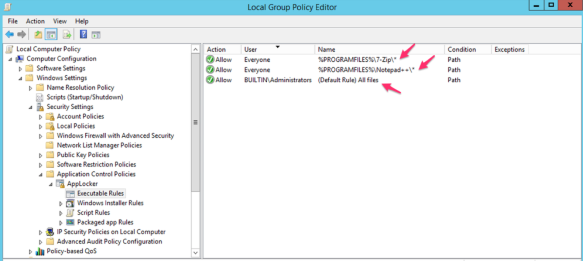
Example screenshot of “Executable Rules” – in this example users (everyone) are allowed ONLY to execute “7-Zip” and “Notepad++” which are installed within “C:\Program Files\” or “C:\Program Files (86)\”; whereas “Administrators” can execute all; there is a “Deny” by default for rest.
Interestingly the same variable “%PROGRAMFILES%” returns both “C:\Program Files\” & “C:\Program Files (x86)”.
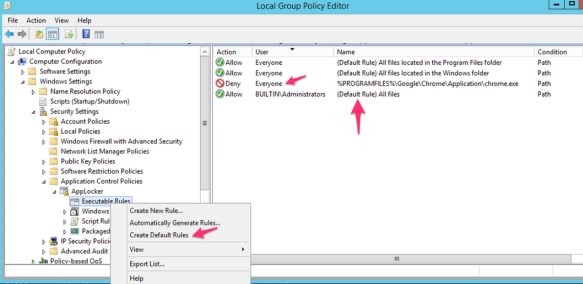
Following screenshot example shows default “Executable rules” which permits everything along with a rule to deny “Google Chrome” for everyone including Administrators; deny overrides other options.
Set the Script Rules
Script rules options are same as the executable rules – Publisher, Path and File Hash along with Allow or Deny. Also, you can create default rules which allows everything.
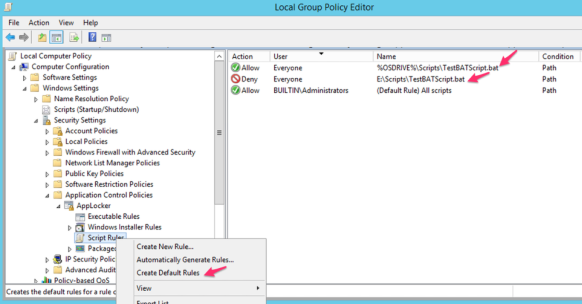
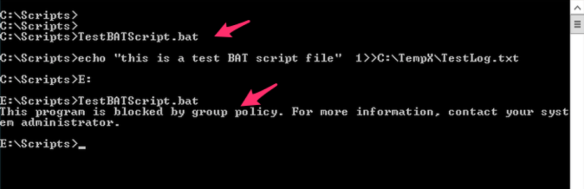
Following “Script Rules” screenshot shows the same BAT file “TestBATScript.bat” is allowed on the %OSDRIVE% which is the “C:\Scripts” for users and denied on the “E:\Scripts\” for everyone.
If the above settings are pushed via GPO – it requires some time to applied to the destinations computers. This can be forced or the destination computer can be rebooted to get these settings immediately pushed.
Also, if we remove AppLocker settings on a computer – this takes few minutes (2-5min) to take effect as well; don’t expect result immediately.
Step3: Verification
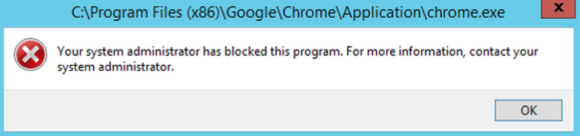
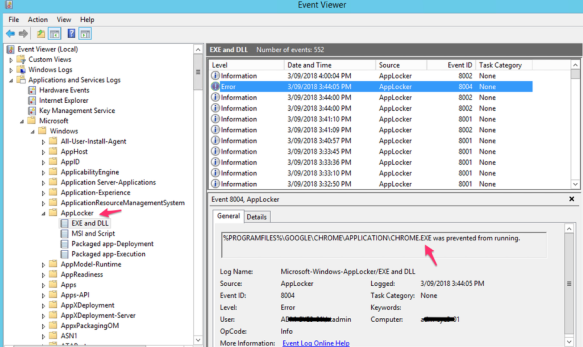
As we have configured “Deny” on the “Google Chrome” for all users – it will pop-up with the following error message when someone tries to open it up –
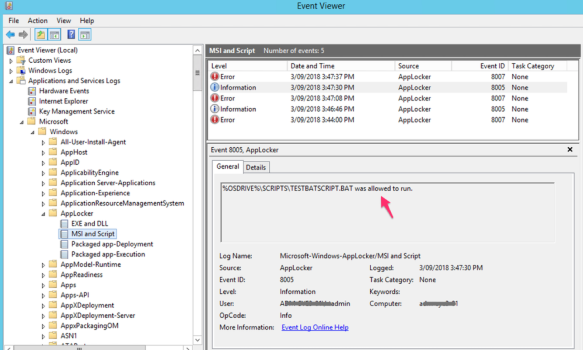
Also, we have configured the “TestBATScript.bat” to allow execute from “C:\Scripts” and deny from “E:\Scripts\”; following screenshot says it all –
Part 2 – Visibility and Analytics of Application Whitelisting using Splunk
A complete real time visibility and analytics of application executables and scripts across all the servers (100+ servers) are important to support the platform. Following are interesting items to application whitelisting analytics –
- Who is executing what application
- On what servers/system
- What application are allowed
- What application are denied
- When/What time an application executed
- Knowing the system applications
- Knowing user defined applications
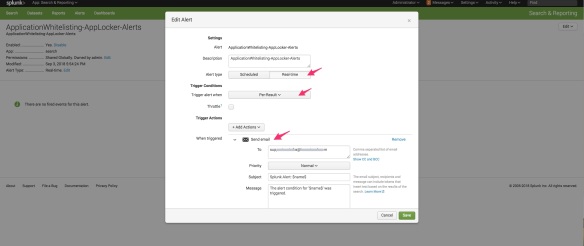
- Sending alert email when an application/script execution is blocked
The above key interesting items about application whitelisting are available within AppLocker Windows Event Log files; the location of these logs are at Event Viewer -> Application and Services Logs -> Microsoft -> Windows -> AppLocker (EXE and DLL; MSI and Script). Example screenshots are following –
To get real time analytics of what’s happening within AppLocker onto Splunk – we need to redirect AppLocker logs onto -> Splunk using the “Splunk Universal Forward”.
Setup Splunk Universal Forwarder (SUF)
SUF is free downloadable from www.splunk.com; download and install it on the target Windows computer. Ideally, it should be part of base Windows OS build template – so that we don’t need to install it manually every time.
During the SUF installation – we select the following “Security Log” only; although this is not a requirement for AppLocker to select security log; however, selecting security logs fulfil many compliance requirements. Select other type logs based on business requirements; also event logs selection can be done later on after the installation.
Make sure your Splunk server is up and running.
[select Windows Event Logs]

Enter the Splunk server IP address and receiving port number to redirect logs to.
[Enter the destination Splunk receiving server and port number]

After the installation – add the following lines onto the SUF local site config file “C:\Program Files\SplunkUniversalForwarder\etc\system\local\input.conf” –
[WinEventLog://Microsoft-Windows-AppLocker/EXE and DLL] disabled = 0 evt_resolve_ad_obj=1 [WinEventLog://Microsoft-Windows-AppLocker/MSI and Script] disabled = 0 evt_resolve_ad_obj=1
The above lines will redirect AppLocker “EXE and DLL” and “MSI and Script” logs onto -> Splunk; the “evt_resolve_ad_obj=1” will allow identify/show Active Directory user names.
Restart the SUF service.
At this stage AppLocker logs will start flowing onto the Splunk; based on index settings Splunk will automatically add these log entries onto the respective index or to the default index.
Following are few examples of AppLocker analytics dashboards within Splunk –
Screenshot of who/what action/what application/when/from is following; Splunk search string for this:
source="WinEventLog:Microsoft-Windows-AppLocker/*"| table host, User, Type, Message, _time

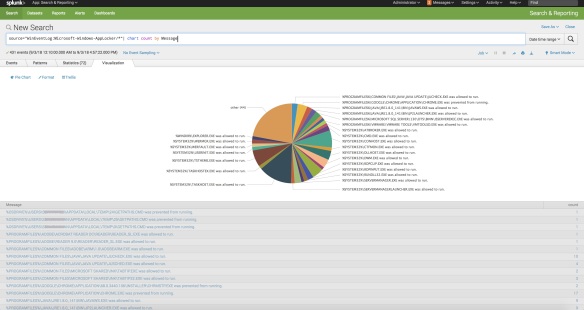
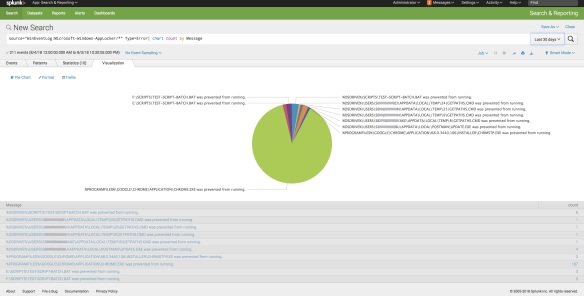
Screenshot of total number of applications following; Splunk search string for this –
source="WinEventLog:Microsoft-Windows-AppLocker/*"| chart count by Message
Screenshot of total number of denied applications is following; Splunk search string for this –
source="WinEventLog:Microsoft-Windows-AppLocker/*" Type=Error| chart count by Message
Screenshot of email alert when there is a deny following; Splunk search string is following –
source="WinEventLog:Microsoft-Windows-AppLocker/*" Type=Error | table host, User, Message, _time
[Screenshot of Splunk alert email triggered on deny condition]
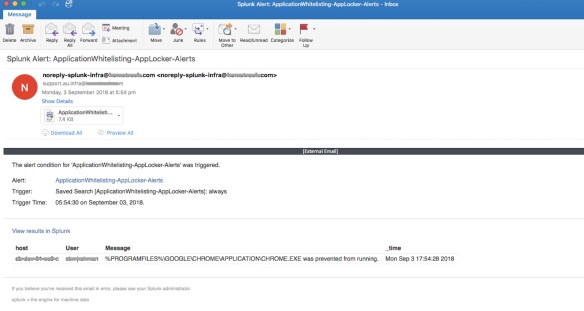
One of the key reason for alert emails – incase any “required” apps missed out from whitelisting – you will get details of the app even before the end user/team tells you to whitelist it.
Thats ALL!