When we talk about standard NTP server that could provide time sync to cross-platform infrastructure objects such as Windows, Linux, Unix, Cisco, HP, F5, VMware etc – a lot of us prefer Linux based NTP server. However, a Windows based NTP server is also equally capable of providing cross-platform time sync just like a Linux NTP and very easy to configure. I assume when people think of cross-platform – they think Windows NTP is only good for Microsoft environment which actually not true.
I often do install and configure centralized NTP sync for customers. Previously I was always stick to Linux based NTP – however, few Windows shop customers pushed me to find a suitable solution for the same on Windows server, hence I come across this; I found this is working perfectly and very stable. There is no 3rd party software required to get this done on Windows 2003/2008/2012 Servers.
Here is below step-by-step configuration – most of these configurations are based on registry settings – to edit registry use “regedit” utility.
In this doco I have discussed the following –
1. How to configure a stand-alone NTP server on a Windows 2008/2012 Server
2. How to configure NTP service on Window AD DS environment
3. How to configure NTP sync to a non-domain joined Windows computer acting as a NTP client.
1. Configure a stand-alone NTP server on a Windows 2008/2012 Server
Following configuration will enable “NTP server” service on a stand-alone Windows 2008/20012 Server (this is equivalent as a stand-alone Linux based NTP server) –
i. Enable “NTP server” service on the machine-
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders\NtpServer
Set the value data to: 1; Default value is 0 – which means NTP server service is not enabled.
ii. Change the server type to NTP on this machine-
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters\Type
Set the value data to: NTP; This is “standard” NTP server that can provide time sync to cross-platform. Other value for this is “NT5DS” – which depends on active directory.
iii. Set the announce flag-
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\AnnounceFlags
Set the data value to: 5; value 5 means – sync time to an external time source. Default value is 10 – this tells the server to sync time to local CMOS clock.
iv. Specify external time sync peers-
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters\NtpServer
Set the value to: 0.pool.ntp.org,0x01 1.pool.ntp.org,0x01 2.pool.ntp.org,0x02 (these are free public NTP servers on the Internet) or your preferred external NTP servers. Make sure you maintain a white space between servers.
The “0x01” flag indicate sync time with external server in special interval configured in “SpecialPollInterval” registry value.
Value “0x08” means – use client mode association while sync time to external time source.
Value “0x09” means – use special interval + client mode association to external time source. This is a good value when your machine sync time to an external time source.
Value “0x02” means – use this as UseAsFallbackOnly time source – if primary is not available then sync to this server.
Value “0xa” means – UseAsFallbackOnly + client mode association.
v. Set time sync pool interval (special interval) –
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders\NtpClient\SpecialPollInterval
Set the value to: 900; Microsoft TechNet & lots of other reference documents recommend a value of 900 seconds (every 15 min).
vi. Set the time correction settings-
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\MaxPosPhaseCorrection
Set the value to: 3600; Microsoft recommends a value of 3600 or 1800 seconds. On ADDS domain controllers Microsoft suggest to set this value to 48 hours (172800 seconds).
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\MaxNegPhaseCorrection
Set the value to: 3600; Microsoft recommends a value of 3600 or 1800 seconds. On ADDS domain controllers Microsoft suggest to set this value to 48 hours (172800 seconds).
Original description for this time correction is > “Specifies the largest positive time correction, in seconds, that the Windows Time service is allowed to make. If the service determines that a change larger than this is required, then the service logs an event instead”.
vii. Make sure to restart windows time server called “w32time”-
>net stop w32time
>net start w32time
viii. Make sure to start Windows Time service to start automatically with operating system reboot.
Services.msc > Windows Time > Startup Type > Automatic.
At this stage all the required registry settings are DONE – this server is ready to serve as a standard NTP server that can provide time sync to cross-platform.
Let’s verify NTP server configurations are entered correctly and the NTP server is syncing time to external source correctly –
>w32tm /query /status /verbose; this will display last sync status or any error

>w32tm /query /peers; this will display NTP external peers
>w32tm /query /source; this will display current NTP time source
>w32tm /query /configuration; this will display current configurations
>w32tm /resync; this will force immediate time resync
2. Configure NTP Service on Window AD DS Environment
Windows Active Directory time sync works a bit differently – not all the domain controllers are responsible to sync time to external time sources. Only the domain controller have the PDC emulator role sync time to external time sources. NTP server service is enabled by default on PDC emulator.
Active Directory Domain Service time sync flow is following –
External time sources>> Domain Controller with PDC emulator>> all other Domain Controllers>> all domain members.
The external time sources can be the standalone NTP server just been described in the above section 1 – or this can be NTP servers sitting on the Internet. Make sure you have outbound internet connection allowed for the DC with PDC role – also windows firewall not blocking NTP in/out on this DC.
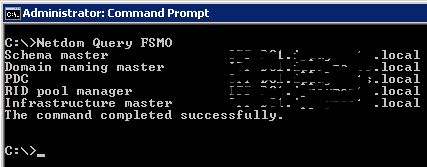
To find out which domain controller is PDC emulator – execute “Netdom Query FSMO” command –
Following settings will make the PDC emulator DC to sync time to external time source –
>w32tm /config /update /syncfromflags:manual /manualpeerlist:myntp01.test.local,0x09
Or edit the registry value “NtpServer” and enter NTP servers DNS address.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters\NtpServer
The above command tells the server to sync time to myntp01.test.local.
“0x09” flag tells the server to use a client-mode association with special interval.
>w32tm /config /reliable:yes /update
This command tells the PDC emulator server to mark itself as reliable time source to domain member computers.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders\NtpClient\SpecialPollInterval
Set the value to: 900; Microsoft & lot of other documents recommend a value of 900 seconds (every 15 min).
Set the time correction settings –
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\MaxPosPhaseCorrection
On ADDS domain controllers Microsoft suggest to set this value to 48 hours (172800 seconds). I found default value is set to 3600 seconds.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\MaxNegPhaseCorrection
On ADDS domain controllers Microsoft suggest to set this value to 48 hours (172800 seconds). I found default value is set to 3600 seconds.
Finally restart windows time service.
>net stop w32time
>net start w32time
Configure all other domain controllers to use time sync from Active Directory Hierarchy automatically. The following commands need to be executed on every non-PDC emulator domain controllers –
>w32tm /config /syncfromflags:domhier /update
At this stage ALL AD DS domain controllers are ready to serve time sync to all domain members.
Verify configuration by using “w32tm /query /status /verbose” and also check “system logs” in the “event viewer” for any w32time warning or error.
No configuration need to be done on domain members – if you execute “w32tm /query /source” on a domain member – this should return FQDN of a domain controller.
3. Configure NTP Sync to a Non-Domain Joined Windows Computer as NTP Client
Sometimes you might find non domain join Windows computers that need be to configure time sync to NTP server(s). The NTP server can be the one configured at section 1 or can be NTP servers sitting on Internet – make sure windows firewall configuration allow NTP sync.
Change the following registry value to configure time sync to an external server –
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config\AnnounceFlags
Set the data value to: 5; Default value is 10.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders\NtpClient\SpecialPollInterval
Set the value to: 900; Microsoft recommends a value of 900 seconds (every 15 min).
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters\NtpServer
Enter myntp01.test.local,0x09 or your preferred external NTP server address; this can be IP address instead of DNS name as well.
You can also enter “time correction” registry values described in the above sections.
Now restart windows time service –
>net stop w32time
>net start w32time
Check Windows event logs and “w32tm /query” commands to make sure time sync is working fine.
4. Reset NTP Registry Settings to the Default
There might be some situation when you need to reset NTP related registry settings to Windows default values; following are the commands –
>net stop w32time
>w32tm /unregister
>w32tm /register
>net start w32time